

به گزارش ساوت چاینا مورنینگ پست، علیبابا کلود که شاخه هوش مصنوعی و رایانش ابری علیبابا به شمار میرود، چند روز پیش نسل جدیدی از مدلهای زبانی بزرگ (LLM) را رونمایی کرد که تقریبا ۱۳ برابر کوچکتر از بزرگترین مدل هوش مصنوعی خود این شرکت هستند.
مدل جدید کوئن۳ نکست ۸۰بی ای۳بی (Qwen3-Next-80B-A3B) نام دارد و سازندگانش میگویند که با وجود اندازه کوچکش، یکی از بهترین مدلهای علیبابا تا به امروز محسوب میشود.
مهمترین ویژگی این مدل کارایی بالای آن است، به طوری که گفته میشود برخی کارها را ۱۰ برابر سریعتر از مدل قبلی یعنی کوئن۳ ۳۲بی انجام میدهد و هزینههای آموزش آن هم ۹۰ درصد کمتر است.
به گفته بنیانگذار یک شرکت نوپای هوش مصنوعی در انگلیس، عملکرد مدل جدید علیبابا تقریبا از تمام مدلهایی که در سال گذشته عرضه شدند بهتر است و در عین حال آموزش آن نیز هزینه بسیار پایینی دارد (که کمتر از ۵۰۰ هزار دلار تخمین زده میشود).
برای مقایسه کافیست بدانیم که طبق ارزیابیها، آموزش جمینای اولترا گوگل حدود ۱۹۱ میلیون دلار هزینه در بر داشته است.
یکی از شرکتهای معتبر در زمینه محکزنی مدلهای هوش مصنوعی اعلام کرده که کوئن۳ نکست ۸۰بی ای۳بی از جدیدترین نسخه دو مدل آر۱ (R1) ساخت دیپ سیک و کیمی کی۲ (Kimi-K2) ساخته شرکت نوپای مونشات ایآی (Moonshot AI) – که توسط علیبابا پشتیبانی میشود – پیشی گرفته است.
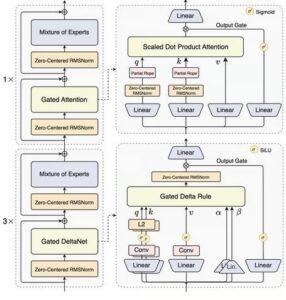
تعدادی از کارشناسان، موفقیت مدل جدید علیبابا را ناشی از بهکارگیری تکنیکی نسبتا جدید به نام «توجه ترکیبی» (hybrid attention) میدانند.
تاکنون نحوه تعیین مهمترین و مرتبطترین ورودیها در مدلهای هوش مصنوعی به شکلی بوده است که با طولانیتر شدن ورودیها، کارایی کاهش مییابد. در این مکانیسم «توجه»، افزایش دقت توجه مستلزم انجام محاسبات و رایانش بیشتر است؛ و زمانی که مدل با ورودیهای طولانی مواجه باشد، حجم رایانش هم بیشتر و بیشتر میشود و در نتیجه آموزش عاملهای (agents) هوش مصنوعی پیچیده که به طور مستقل و خودمختار وظایف مشخص شده از سوی کاربر را انجام میدهند، بسیار پرهزینه خواهد بود.
کوئن۳ نکست ۸۰بی ای۳بی برای حل این مشکل از تکنیکی به نام شبکه دلتای فیلتر شده یا دروازهای (Gated DeltaNet) استفاده میکند که پژوهشگران موسسه فناوری ماساچوست و شرکت انویدیا در ماه مارس سال جاری آن را ابداع نمودند.
در این تکنیک، با ایجاد اصلاحاتی هدفمند در دادههای ورودی و تعیین این که کدام اطلاعات را باید نگه داشت و کدام را باید کنار گذاشت، توجه مدل بهبود پیدا میکند و به این ترتیب یک مکانیسم توجه دقیق و کمهزینه به دست میآید.
علیبابا با استناد به امتیازات به دست آمده در محکزنی رولر (Ruler) که به مدلهای هوش مصنوعی بر اساس تواناییشان در پردازش ورودیهایی با طولهای مختلف امتیاز میدهد، اعلام کرده که کوئن۳ نکست ۸۰بی ای۳بی با وجود اندازه کوچکتر و هزینه کمتر، با قدرتمندترین مدل قبلی خودش یعنی کوئن۳ ۲۳۵بی ای۲۲بی تینکینگ ۲۵۰۷ (Qwen3-235B-A22B-Thinking-2507) قابل مقایسه است.
یکی از متخصصان آلمانی که در دهه ۱۹۹۰ در طراحی شبکههای دلتا یا دلتانتها مشارکت داشت و در حال حاضر استاد دانشگاه علم و صنعت ملک عبدالله عربستان است، میگوید خیلی خوشحالم که میبینم علیبابا دلتانتهای ما را این طور توسعه داده تا با کمک آن مدلهای هوش مصنوعی فوقالعادهای بسازد.
کوئن۳ نکست ۸۰بی ای۳بی از معماری ترکیب متخصصان (MoE) هم بهره میبرد که طی یک سال گذشته باعث افزایش چشمگیر کارایی مدلهای هوش مصنوعی چینی (از جمله دیپ سیک وی۳ و کیمی کی۲) شده است.
در معماری MoE، یک مدل به زیرشبکهها یا «متخصصان» مجزایی تقسیم میشود که در زیرمجموعههای مختلف دادههای ورودی تخصص دارند و در کنار هم وظایف محوله را انجام میدهند.
علیبابا «خلوتی» یا «پراکندگی» (sparsity) جدیدترین معماری MoE خود را افزایش داده است تا کارایی آن بهبود یابد. دیپ سیک وی۳ و کیمی کی۲ به ترتیب ۲۵۶ و ۳۸۴ متخصص دارند. این عدد در کوئن۳ نکست ۸۰بی ای۳بی به ۵۱۲ رسیده است، ولی در هر لحظه فقط ۱۰ عدد از آنها فعال میشوند.
نوآوریهای مذکور موجب شدهاند که مدل جدید با تنها ۳ میلیارد پارامتر فعال، توانی قابل مقایسه با مدل دیپ سیک وی۳٫۱ (با ۳۷ میلیارد پارامتر فعال) داشته باشد. معمولا بیشتر بودن تعداد پارامترها نشان دهنده قدرت بیشتر مدل است، ولی هزینههای آموزش و اجرای آن را نیز بالا میبرد.
این معماری جدید، علاقه روزافزون صنعت هوش مصنوعی به مدلهای کوچکتر اما کارآمدتر را نشان میدهد، چرا که هزینه مدلهای بزرگ به شکل سرسامآوری در حال افزایش است.
پرهزینهترین آموزشی که تا امروز برای مدلهای هوش مصنوعی انجام شده مربوط به گراک ۴اچ (Grok 4h) ساخته شرکت اکسایآی بوده که ۴۹۰ میلیون دلار هزینه داشته است، و انتظار میرود این مبلغ در مراحل بعدی و تا سال ۲۰۲۷ از یک میلیارد دلار هم فراتر برود.
در ماه اوت محققان انویدیا در مقالهای عنوان کردند که با توجه به انعطافپذیری و کارایی مناسب مدلهای زبانی کوچک، بهتر است آینده هوش مصنوعی خودمختار بر پایه این نوع مدلها بنا نهاده شود. این شرکت مشغول آزمایش تکنیک شبکه دلتای دروازهای بر روی مدلهای نموترون (Nemotron) خود نیز هست.
از سوی دیگر غولهای هوش مصنوعی چینی در تلاش برای گسترش بازارشان، سعی دارند مدلها را آنقدر کوچک کنند که روی لپتاپها و تلفنهای هوشمند هم قابل اجرا باشد.
ماه گذشته شرکت نوپای چینی زد.ایآی (Z.ai) مدلی به نام جیالام ۴٫۵ ایر (GLM 4.5 Air) را با تنها ۱۲ میلیارد پارامتر فعال عرضه کرد و هلدینگ تنسنت هم چهار مدل متنباز را عرضه نمود که هر کدام کمتر از ۷ میلیارد پارامتر دارند.
کوئن۳ نکست ۸۰بی ای۳بی علیبابا هماکنون آنقدر کوچک هست که بتوان آن را فقط با یک واحد پردازش گرافیکی اچ۲۰۰ (H200) انویدیا اجرا کرد. این مدل پس از انتشار در یکی از پلتفرمهای آنلاین، ظرف ۲۴ ساعت تقریبا ۲۰ هزار بار دانلود شد.
علیبابا اعلام کرده که معماری جدید، پیشدرآمدی بر نسل بعدی مدلهای هوش مصنوعی آن است. یکی از کارشناسان امپریال کالج لندن میگوید که حتی اگر معماریهای کاملا متفاوت دیگری هم به وجود آیند، احتمالا همین راهکاری که علیبابا برای مدیریت هزینههای آموزش و بهبود کارایی در پیش گرفته است، مسیر آینده مدلهای زبانی بزرگ را شکل خواهد داد.
منبع: scmp

